
Delete Duplicate Rows from Amazon Redshift Database Table using SQL
In this Amazon Redshift tutorial for SQL developers I want to show how to delete duplicate rows in a database table using SQL commands. Just like the case for many data warehouse platforms, although Amazon Redshift database supports creation for primary key, foreign key constraints Redshift does not enforce these constraints. Unique key, primary key, foreign key and other constraints are enforced on OLTP (On-line Transaction Processing) database platforms to ensure data integrity. On the other hand, on OLAP data platforms (OLAP stands for On-line Analytical Processing), these constraints are optional.
Especially even the database enforces these constraints, for the sake of performance especially during data ingestion step, I mean while inserting huge amount of data into the data warehouse it is best practise to disactivate or disable the constraints on the target database table and then import data or copy data from external source into database table. At this step, while data import is completed and it is time to validate and ensure the data quality, database SQL developers and database administrators can try to active the constraints on table level. If there are duplicate rows for example, these will prevent the activation of the constraints.
In this Amazon Redshift SQL tutorial, I want to demonstrate how to identify duplicate records in a Redshift database table and delete duplicates rows or remove duplicates from Redshift table using SQL.

For the sample data, I will create a database table on Amazon Redshift using following SQL Create Table DDL script
create table kodyaz.venue
(
venueid smallint not null distkey sortkey,
venuename varchar(100),
venuecity varchar(30),
venuestate char(2),
venueseats integer
);
If SQL developers refer to Create Sample Database on Amazon Redshift Cluster with Sample Data, they will find the Create Table SQL commands and COPY commands to insert data from public available text files for sample database creation on an Amazon Redshift cluster.
Now I have 202 rows in my sample Redshift database table. Here below, database users can see some of the records. I still don't have any duplicates here.
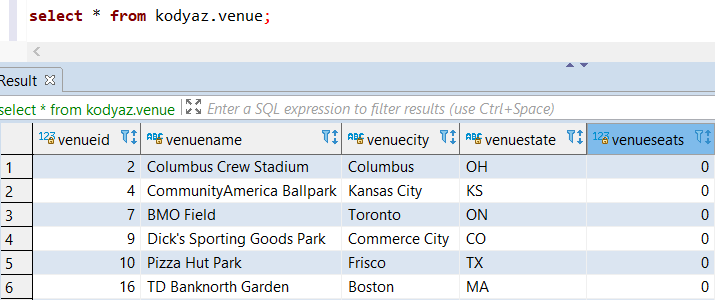
Now by purpose, I will introduce duplicate rows using below SQL Insert command.
Following INSERT INTO ... SELECT FROM command will add existing 10 randomly chosen rows from the same table
insert into kodyaz.venue
select * from kodyaz.venue order by random() limit 10;
After the first execution, I have some rows in the sample database table duplicated twice. If I am lucky enough, after executing the SQL Insert command for 5 times, I can have some rows maybe repeated more then twice in the sample Redshift table.
Identify and Select List of Duplicate Rows in Redshift Table using SQL
Now in my sample table, I have 252 rows.
In my Redshift table I have a column named "venueid" which helps me to identify duplicate or repeated rows.
So whenever there is a second row with venueid from previous rows, I can assume and claim that this record is a duplicate record.
Executing following SQL SELECT statement on Redshift database can help to list duplicate rows.
with duplicates_cte as (
select COUNT(*) OVER (PARTITION BY venueid) as total_duplicates, * from kodyaz.venue
)
select * from duplicates_cte where total_duplicates > 1
order by total_duplicates desc, venueid asc;
Here is the result.
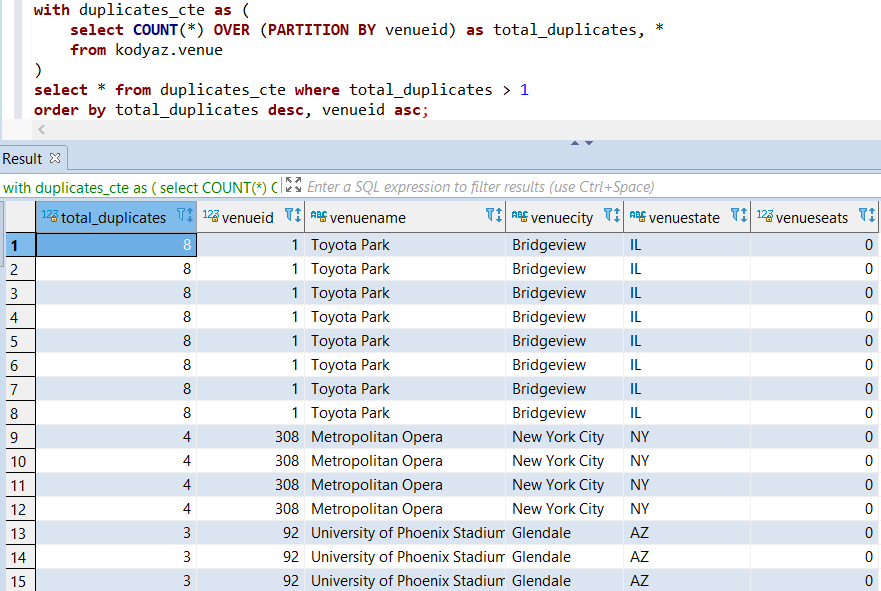
In my sample database table, I observe that the row with ID value equals to 1 has been 8 times counted.
There are total 4 rows with same ID value of 308 and its data.
And the list continues.
Let's now delete duplicates from Redshift table keeping only one copy from each duplicate set.
By changing the above SQL query a bit, data warehouse developers can get a more handy data set as follows
with duplicates_cte as (
select
COUNT(*) OVER (PARTITION BY venueid) as total_duplicates,
ROW_NUMBER () OVER (PARTITION BY venueid) as duplicate_rn, *
from kodyaz.venue
)
select * from duplicates_cte where duplicate_rn > 1
order by total_duplicates desc, venueid, duplicate_rn;
As seen below I numbered each repeating row using ROW_NUMBER() function and listed only the ones with value is equal or greater to 2
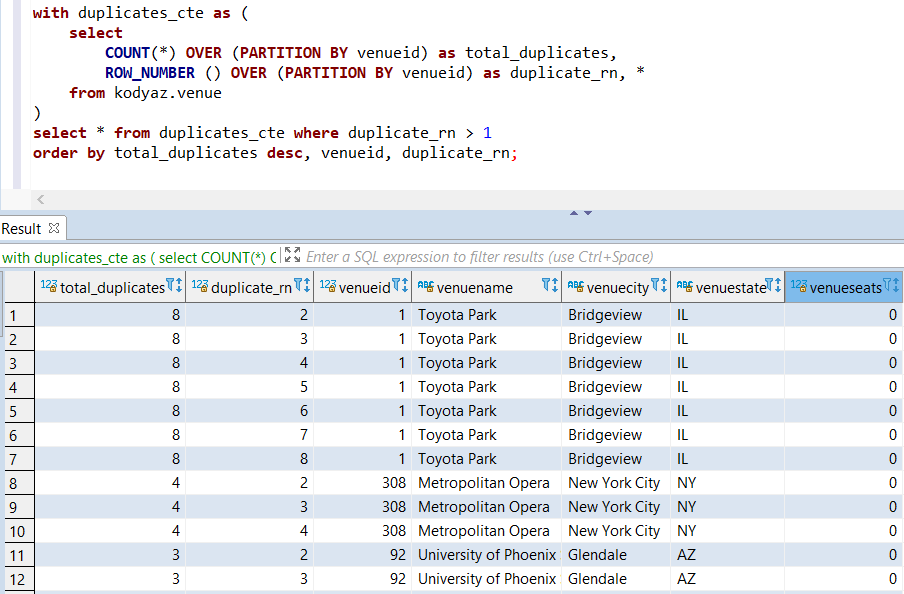
This list contains the records that we will get rid of by removing from the sample Redshift table.
Remove Duplicates from Redshift Database Table using SQL
The procedure that SQL developer can follow to delete duplicate rows on an Amazon Redshift database table I will suggest in this SQL tutorial is as follows:
1) Identify duplicate rows
2) Store a copy of duplicated records in a separate table
3) Using original table and duplicated rows table, clear duplicated from source table
4) Insert back duplicated rows into source table
5) Drop duplicated rows table
By executing below SQL statement, database developers will select only one of the duplicate rows (by filtering with duplicate_rn=1 criteria) and insert these rows in a new Redshift table created during execution. We can think this table as a backup table too. Because the following step will be deleting all rows from the source table for the duplicated rows set.
with duplicates_cte as (
select
COUNT(*) OVER (PARTITION BY venueid) as total_duplicates,
ROW_NUMBER () OVER (PARTITION BY venueid) as duplicate_rn, *
from kodyaz.venue
)
select * into kodyaz.venue_duplicates
from duplicates_cte
where
total_duplicates > 1 and duplicate_rn = 1;
Now we can remove the duplicate rows from venue table using the temporarily created venue_duplicates table in our Redshift database schema.
Please note, below SQL syntax to delete rows from a database table where it is joined with another table on Amazon Redshift databases. On other database platforms like SQL Server, developers can also use DELETE FROM command with different syntax which are not compatible with Redshift database SQL. On the other hand below command can be successfully executed on Redshift databases.
delete from kodyaz.venue
using kodyaz.venue_duplicates
where kodyaz.venue_duplicates.venueid = kodyaz.venue.venueid;
Now we have deleted all the rows which are dublicated including the original rows too by using DELETE command and USING clause.
So whatever you call either backup table or staging table for duplicate elimination, we need to move or copy data from venue_duplicates table into venue table back.
Since we had introduced two additional columns in duplicates table, we had to explicitely list all tables in below INSERT INTO command.
INSERT INTO kodyaz.venue (
venueid, venuename, venuecity, venuestate, venueseats
)
SELECT
venueid, venuename, venuecity, venuestate, venueseats
FROM kodyaz.venue_duplicates;
After this data insertion we have all the data which we had at the beginning except the duplicates.
Amazon Redshift data warehouse SQL developers and administrators can now validate all duplicate rows are deleted from the original table and there is no additional duplicate record in the source table just by executing below SQL command.
with duplicates_cte as (
select
ROW_NUMBER () OVER (PARTITION BY venueid) as duplicate_rn, *
from kodyaz.venue
)
select * from duplicates_cte where duplicate_rn > 1;
The result set should be an empty list otherwise you had something wrong while implementing the above steps or your case is different from the case that we haved solved in this tutorial.
If you execute a SQL query to count all the rows in source database table using COUNT() function, you will see we have again the 202 rows which is the original rows count at the beginning of this Redshift tutorial.
Now we can delete the duplicates table in our Redshift database schema using DROP TABLE command as follows:
drop table kodyaz.venue_duplicates;
I hope this SQL tutorial for Redshift database developer and administrators is useful for removing duplicate rows from Redshift database tables.
Please note that in data warehouse solutions window functions can be very costly and may cause materialization or temporarily storing of intermediate results like sub-queries or Common Table Expressions (CTEs).
In order to reduce consumed database resources, SQL programmers can minimize the field list in the SELECT statements which help us to identify whether a row is unique or not.