
What Is Amazon Redshift Data Warehouse?
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud.
This is the first definition of Amazon Redshift provided by AWS. With time and new features and properties added to Amazon Redshift a second definition is being preferred for Amazon Redshift. Here it is:
Amazon Redshift is a fast, fully managed, and cost-effective data warehouse that gives you petabyte scale data warehousing and exabyte scale data lake analytics together in one service.
An other definition which can be used for Redshidt is: Amazon Redshift is a column based database designed for OLAP allowing customers combine multiple complex queried to provide answers
![]()
Before we start talking on Amazon Redshift, I have noted the Power Point presentation I have prepared before on Amazon Redshift and decided to publish via this Redshift tutorial. The original presentation can be downloaded from here What is Amazon Redshift?
Just a small guide for comparing data sizes in internet: Megabyte -> Gigabyte -> Terabyte -> Petabyte -> Exabyte -> Zettabyte -> Yottabyte
What is a Data Warehouse
Since Amazon Redshift is considered as a data warehouse service in the cloud, let's continue with definition of a data warehouse.
A data warehouse is any system that collates data from a wide range of sources within an organization.
Data warehouses are used as centralized data repositories for analytical and reporting purposes.
Here comes the relational and non-relational databases concept.
Relational Databases are diveded into OLTP an OLAP databases.
Non-Relational Databases: NoSQL - Schema-free, horizontally scalable, distributed across different nodes.
Redis, DynamoDB, Cassandra, MongoDB, Graph databases are samples of non-relational databases.

For more on Data Warehouse concepts please refer to following resources:
Data Warehouse Concepts
Difference between RDS, DynamoDB, Redshift
What is a DBMS?
Amazon Redshift Features
Let's try to list some of the features of Amazon Redshift.

Cost-effective: Costs less than 1000$ per terabyte per year. 10 times less than traditional data warehouse solutions (Google BigQuery 720$, Microsoft Azure 700+$)
Pay for Compute Node Hours (Lead node is not chargable)
Data transfers within your VPC is not charged between S3 and Redshift (Load unload backup snapshot). Data transfers outside of your VPC is charged. Backups are free up to a provisioned amount of disk.
For pricing check:
Amazon Redshift pricing
S3 Calculator
The True Cost of Building a Data Warehouse
Fast: Columnar storage technology in MPP massively parallel processing architecture to parallelize and distribute data and queries across multiple nodes consistently delivering high performance at any volume of data
Compatible: Supports ODBC and JDBC connections, and existing BI tools are supported
Simple:
Uses ANSI SQL for querying data, PL/pgSQL for stored procedures
Some use Spark SQL->different; HiveQL->similar; GQL->similar
To manage Redshift following tools can be used:
Amazon Redshift console
AWS Command Line Interface (AWS CLI)
Amazon Redshift Query API
AWS Software Development Kit (SDK)
Petabyte-Scale DW: 128 nodes * 16 TB disk size = 2 Pbyte data on disks. Additionally Spectrum enables to query data on S3 without limit featuring exabyte scale data lake analytics
Fully Managed: Cloud SaaS Data Warehouse service
Automating ongoing administrative tasks (backups, patches)
Continuously monitors cluster
Automatic recover from disk and drive failures (data itself, replica on other compute node, S3 incremental backups)
Scailing without downtime for read access (adds new nodes and redistributes data for maximum performance)
Secure: Encryption (at rest and in transit including backups), VPC (compute nodes in a separate VPC than leader node so data is separated seamlessly)
Redshift is not highly available. It is available only in one availability zone
On the other hand you can restore snapshots of Amazon Redshift databases in other AZs
Some other points to note here can be:
No Upfront Investment,
Low Ongoing Cost,
Flexible Capacity,
Speed & Agility
Apps not Ops,
Global Reach
Anti-Patterns of Data for Amazon Redshift
Amazon Redshift is not for:
Small datasets:
If your dataset is less than 100 gigabytes, you’re not going to get all the benefits that Amazon Redshift has to offer and Amazon RDS may be a better solution
OLTP: Use an RDS or NoSQL solution if your requirement is an OLTP database
Amazon Redshift is designed for data warehousing workloads delivering extremely fast and inexpensive analytic capabilities. For a fast transactional system a traditional relational database system built on Amazon RDS or a NoSQL database such as Amazon DynamoDB can be a better option
Unstructured data:
Redshift requires defined data structure. It cannot be used for dat with arbitrary schema structure for each row
BLOB data: If you plan to use Binary Large Object (BLOB) files such as digital video, images, or music files then store the object itself in Amazon S3 and reference it in Amazon Redshift
Please refer to Data Warehousing on AWS document for anti data patterns for Amazon Redshift
Magic Quadrant for Data Management Solutions for Analytics
Following evaluations of vendors for the last 3 years by Gartner shows that Amazon is one of the major players providing Data Management Solutions for Analytics (DMSA)

Gartner evaluation states strengths and cautions for Amazon similar to following:
Strengths
Leader in Cloud
Number of resources and services
Number of third-party resources
40% more growth than DMSA
AWS Outposts for on-premises presence
Cautions
Integration complexity
Value for money, pricing and contract flexibility (high scores for evaluation and contract negotiation)
Product capabilities: relatively slow to adopt some key features
Amazon Web Services
Amazon Redshift, a data warehouse service in the cloud.
Amazon Redshift Spectrum, a serverless, metered query engine that uses the same optimizer as Amazon Redshift, but queries data in both Amazon S3 and Redshift’s local storage.
Amazon S3, a cloud object store;
AWS Lake Formation, a secure data lake service;
AWS Glue, a data integration and metadata catalog service;
Amazon Elasticsearch, a search engine based on the Lucene library.
Amazon Kinesis, a streaming data analytics service,
Amazon Elastic MapReduce (EMR), a managed Hadoop service;
Amazon Athena, a serverless, metered query engine for data residing in Amazon S3;
Amazon QuickSight, a business intelligence (BI) visualization tool.
Amazon Neptune provides graph capabilities.
Relatively slow to adopt some key features that are expected by modern cloud DMSA environments — such as dynamic elasticity, automatic tuning, and separation of compute and storage resources
Amazon Redshift Architecture
Amazon Redshift is created based on a branch of PostgreSQL (PostgreSQL 8.0.2) and AWS has added analytics features, MPP (massively parallel processing) and columnar storage

Connection string to Amazon Redshift is as PostgreSQL 8.0.2
Redshift programming language is similar to PostgreSQL and compatible ANSI SQL
Since first release of Amazon Redshift in February 2013, it has been improved with biweekly updates

Compute nodes:
Dedicated CPU, memory, and attached disk storage
Increase the compute capacity and storage capacity of a cluster by increasing the number of nodes or upgrading the node type

Leader Node:
Parser
Execution Planner and Optimizer
Code Generator
C++ Code Compiler
Task Scheduler
WLM: Automatic “Work Load Management”
Postgres catalog tables, like pg* tables
Compute Nodes:
Query execution process
I/O and Disk Management
Backup and Restore process
Replication process
Local storage
Please read Redshift Architecture for more on architecture of Amazon Redshift cluster
I/O Reduction
I/O reduction in Amazon Redshift is obtained by using following techniques:
Columnar Storage,
Data Compression,
Zone Maps
Columnar Storage: Columnar storage is effective when a column data is read. Only scans blocks for relevant column

Data Compression:
DDL shows each column can be seperately compressed with different compressing methods
Reduces storage requirements and I/O
Compression is also called Encoding. Read more on Compression Encodings
Up to 4 times of data could be stored with data compression on an Amazon Redshift cluster
Increate query performance by reducing I/O
COPY command applies compression by default

By executing following SQL command, column compression encodings can be displayed for a specific Redshift database table
Select column, type, encoding from pg_table_def where tablename = ‘…’;
Zone maps:
Zone maps are in-memory block metadata, they store minimum and maximum valules of data contained in each block.
Block: 1 MB chunks of data of data stored on cluster storage.
Zone maps are important for performance since they are used to eliminate unnecessary I/O by effectively pruning blocks which don’t contain data for the query

Blocks are immutable. This means blocks are not updated. Only new blocks are written. Please refer to Redshift Pitfalls And How To Avoid Them for UPDATE process behind scenes. Another reference is Updating and Inserting New Data from Amazon AWS documentation.
Zone maps are in memory so before hitting disk we can eliminate unrelated data chunks
Redshift does not support Indexes. Instead, each table has a user-defined sort key which determines how rows are ordered

Data Sorting and SORTKEY
Sort key is used to determine the physical order of table rows data
Picking a Sort Key eliminates I/O by optimizing effectiveness of zone maps
Multiple columns can be used as SortKey
An optimal SORTKEY is dependent on:
- Query patterns,
- Data profile,
- Business requirements
Redshift does not support traditional indexes. Instead, the data is physically stored to maximize query performance using SORT KEYS.
The last SQL line of the following Amazon Redshift database table definition (SQL DDL command) shows how to define a compound sortkey on a Redshift table

Data Distribution
The aim of data distribution on Amazon Redshift cluster is to distribute data evenly for parallel processing performance optimization. Additionally a wisely distributed data will minimize the data movement during SQL query processing.
Data Distribution is defined by Distribution Style and Distribution Key
There are 3 distribution styles:
Key: take a good cardinality column + hash it + write to a slice
Even: data does not have a very good cardinality, so enables to round robin data among slices, a good option when key distribution style does not produce even distribution
All: used for dimension tables, moves data to all nodes (to first slice in every compute node), suitable for small tables < 2-3 MB

Amazon Redshift Data Storage
Amazon Redshift has disk base data storage. Data is distributed to slices on compute node disks.

Disk
More storage on the nodes than advertised.
Advertised (usable size by customer)
Data is mirrored . Always 2 copies of data on disk. Partitions (local CN, remote CN)
When a commit is executed (ie after Insert command) data is stored on two different nodes in the cluster.
2.5-3 times of usable storage: temp area and system tables, etc
Slices: (virtual compute node) computes nodes divided virtually into slices. So parallelism is fetched within each compute node
Blocks
1 MB immutable blocks
11 encodings or more (check)
Zone Maps (Min/Max values)
8-16 million values
Columns
Blockchain (of blocks) for each column on each slice
There are 2 blockchains if you have a sortkey on a table: 1 for sorted region and 1 for unsorted region
Additional columns in a table (system used): row id, deleted id, transaction id (not queriable, for MVCC)
Column properties: Distribution key, Sort key, Compression Encoding

2 PetaBytes of compressed data nearly 6 PetaBytes of data can be managed in a single Redshift cluster
Block Properties
Small writes has similar cost to write commands affecting huge number of rows.
UPDATE = DELETE + INSERT
Since blocks are immutable, data is not physically deleted when a SQL DELETE command is executed for a data row.
A logically delete process or a soft delete takes place.
UPDATE SQL operations cannot modify block data so original data is marked as deleted and new data is inserted into a new data block.
Vacuum: process of cleaning deleted records (similar to HANA database Delta Merge process as purpose)
Column Properties
Table columns have compression options (or encoding). An other column property is distribution key DISTKEY and sort key SORTKEY.
COPY command automatically analyzes data considering minimum size for different encoding types when loading data into empty database tables. SQL developers can manually execute Analyze Compression command to check existing database table and suggests an optimal encoding which provides best compression algorith for each column of that particular table.
As we have mentioned before distribution style and distribution key as well as sort key significantly effect data warehouse performance when a SQL query is executed on that database table.
Poorly chosen distribution key causes data skew (data is not evenly distributed to slices or compute node storage) which causes performance problems since parallelism is not used as desired from the MPP architecture of Amazon Redshift cluster.
While choosing the sortkey to know the profile of the data and SQL queries that will be executed frequently is very important. The sort key columns should be highly selective to get better performance from sort keys to purge data blocks efficiently.
Query Lifecycle
Query LifeCycle
Planner: Execution plans
Optimizer: statistics
Step: individual operations (scan, sort, hash, aggr)
Stream: collection of C++ binaries incuding segments, including steps
One stream should end so following segment can start
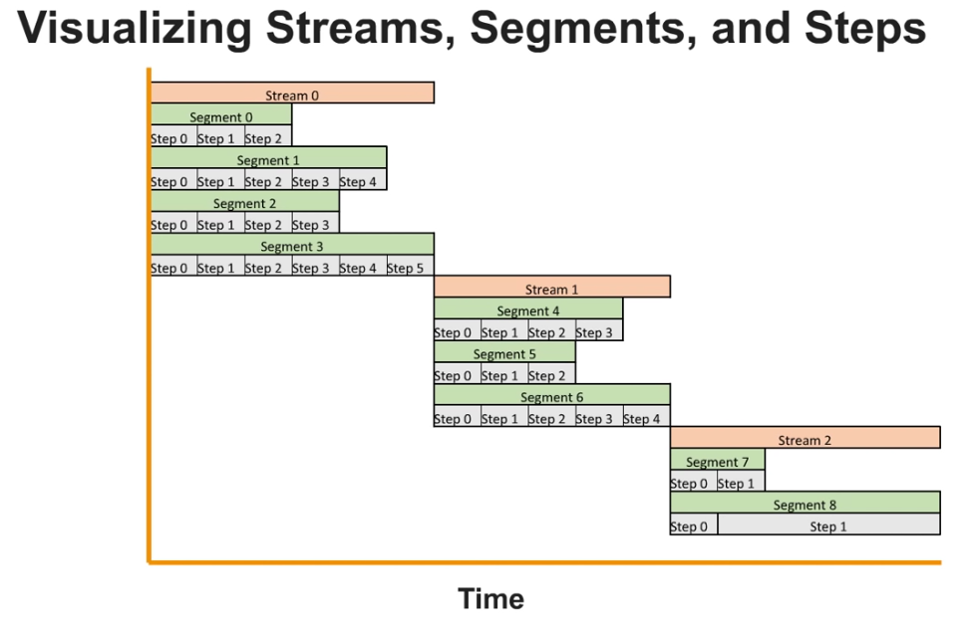
New cycle starts between leader node and compute nodes to process following stream (of C++ code generated) based on results of previous stream

Following document can be referred Analyzing Query Execution for details.

Results send to client
First compilation cause a delay, second executions use compiled code from cache
In maintenance cycle, cache is cleared

Move Data from On-Premise to Redshift
To export on-premise data from source systems to Amazon Redshift, a few methods can be carried.

An option is to transfer data files to Amazon S3 buckets and then to load data from S3 to Amazon Redshift using SQL COPY command.
An other option is using AWS DMS (AWS Database Migration Service)

Multi-File Load with COPY Command
In order to load high volume of data into Amazon Redshift database using SQL COPY command database developer can use the MPP architecture benefits. In single file loads with COPY command, a single slice takes care of the data file import process. If the data is big, it is good to divide source CSV data into multiple files. So each slice can take a separate data file to upload minimizing total process time

To load data faster into Amazon Redshift database divide CSV data into multiple files
Redshift Spectrum
Amazon Redshift Spectrum enables Redshift SQL developers to define data files stored in Amazon S3 bucket folders as external tables and join with Redshift database tables in SQL queries.
Redshift Spectrum extends the peta-byte data scale of Amazon Redshift to exabyte scale. Additionally, with Spectrum feature Amazon Redshift can be considered as a data warehouse solution with query capability of your data lake.

Following diagram shows how Amazon Redshift cluster compute nodes interact with Amazon S3 folders containing data files with Spectrum layer.

How to Connect to Amazon Redshift
There are numerous methods on various database management tools to connect to an Amazon Redshift database. Some of these tools can be listed as;
AWS Amazon Redshift Query Editor
Amazon Redshift API
SQL Workbench/J
SQL Server Management Studio
DataRow
pgAdmin
JackDB

For more, please read Amazon Redshift API Reference and Amazon Redshift - Part 1: Basic Connection